Optical Character Recognition, or OCR, is a technology that allows you to convert different types of documents, such as scanned paper documents, PDF files or images captured by a digital camera, into editable and searchable data.
Casedo offers an internal OCR feature, so you won’t have to do it externally. Through OCR, you will be able to highlight and copy-paste from your text.
To do this:
1. Right-click on the unreadable pdf document.
2. Select ‘Recognise text.’
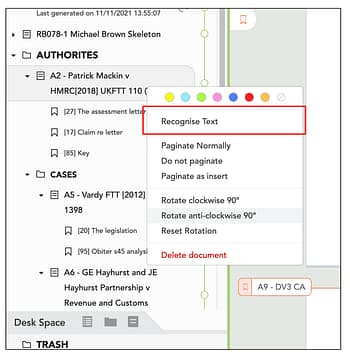
This will immediately prompt Casedo to start reading the document and recognising the text within it.
This feature currently works best with letters and other short documents to a maximum of 60 pages in length and should take an average of 30 seconds to recognise the text on each page of the document. If you want to stop Casedo from searching the unreadable text mid-operation, simply click on the ESC key on your keyboard. Casedo will start cancelling the operation and display a message asking you to wait a few seconds.
You can scan large documents, but keep in mind that the larger your bundle is, the longer it will take to OCR. However, you can always use the split feature to divide larger documents that are difficult to recognise into lengths that can easily be OCR’d. After which, you can simply put them back together again using the merge feature.
N.B. Is it important to note that without OCRing the PDF, you won’t be able to use the Text markup tools such as highlighting or even searching through your documents. This is because before your computer recognises a text as an ‘actual text’, the software detects it as an image or vector objects. If you want to highlight your text, then simply follow the steps above to use the OCR feature.
N.B. The “Recognise Text” option (OCR) is only available when right-clicking on documents and not on bookmarks or folders.
LAST UPDATED 2023.11.13
Optical Character Recognition, or OCR, is a technology that allows you to convert different types of documents, such as scanned paper documents, PDF files or images captured by a digital camera, into editable and searchable data.
Casedo offers an internal OCR feature, so you won’t have to do it externally. Through OCR, you will be able to highlight and copy-paste from your text.
To do this:
1. Right-click on the unreadable pdf document.
2. Select ‘Recognise text.’
This will immediately prompt Casedo to start reading the document and recognising the text within it.
This feature currently works best with letters and other short documents to a maximum of 60 pages in length and should take an average of 30 seconds to recognise the text on each page of the document. If you want to stop Casedo from searching the unreadable text mid-operation, simply click on the ESC key on your keyboard. Casedo will start cancelling the operation and display a message asking you to wait a few seconds.
You can scan large documents, but keep in mind that the larger your bundle is, the longer it will take to OCR. However, you can always use the split feature to divide larger documents that are difficult to recognise into lengths that can easily be OCR’d. After which, you can simply put them back together again using the merge feature.
N.B. Is it important to note that without OCRing the PDF, you won’t be able to use the Text markup tools such as highlighting or even searching through your documents. This is because before your computer recognises a text as an ‘actual text’, the software detects it as an image or vector objects. If you want to highlight your text, then simply follow the steps above to use the OCR feature.
N.B. The “Recognise Text” option (OCR) is only available when right-clicking on documents and not on bookmarks or folders.
LAST UPDATED 2023.11.13